
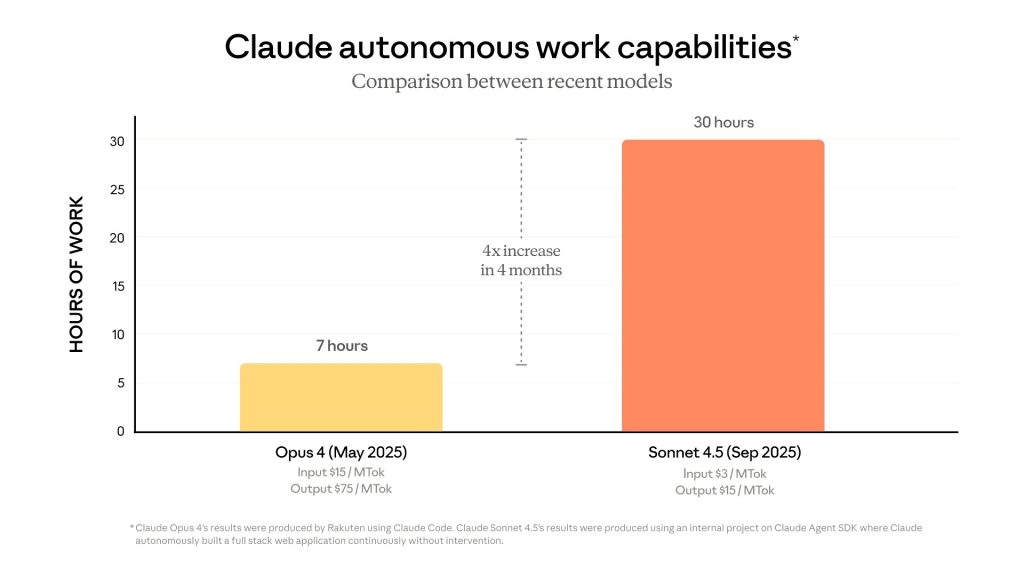
Anthropic rolled out Claude Sonnet 4.5 this week, positioning the AI model as a breakthrough in autonomous programming capabilities that can maintain focus and productivity for over 30 hours straight—more than quadruple its predecessor’s endurance.
The San Francisco-based AI company, backed by Amazon and valued at $183 billion, claims the new model represents “the world’s best coding AI” based on industry benchmark performance. Claude Sonnet 4.5 achieved a 77.2% score on SWE-Bench Verified, a rigorous software engineering assessment that evaluates AI systems against real-world programming challenges.

Extended Work Sessions Transform Development Workflows
The model’s expanded working capacity marks a substantial leap from Claude Opus 4, which could maintain concentration for roughly seven hours when it launched in May. During internal testing, Claude Sonnet 4.5 independently built a complete chat application, generating approximately 11,000 lines of code while maintaining coherence throughout the entire development process.
“Claude Sonnet 4.5 changes our expectations—it handles more than 30 hours of autonomous coding, enabling our engineers to solve challenges that previously required months of complex architectural work in significantly less time, while maintaining integrity across massive codebases,” said Sean Ward, CEO of iGent AI.
Computer interaction tasks also saw dramatic improvements, with the model scoring 61.4% on the OSWorld benchmark—nearly 20 percentage points higher than Claude Sonnet 4’s 42.2% result from just four months earlier. This performance gap suggests accelerating capability growth rather than incremental refinement.
Developer Tools Receive Practical Upgrades
Beyond raw coding performance, Claude Sonnet 4.5 introduces meaningful workflow improvements through expanded tooling and safety mechanisms. The model now supports checkpoints in Claude Code, letting developers save progress and revert to previous states—a feature that topped community request lists. Users can also execute code and generate files including spreadsheets, presentations, and documents directly within conversations, eliminating context-switching between applications.
Anthropic characterizes this as their “most aligned frontier model to date,” with substantial reductions in problematic behaviors like sycophancy, deception, and power-seeking tendencies. The company strengthened defenses against prompt injection attacks, where adversaries attempt to manipulate AI systems through carefully crafted inputs. These security enhancements accompany the release of Claude Agent SDK, giving developers the same infrastructure powering Claude Code to build custom autonomous agents capable of managing memory, controlling access permissions, and coordinating multiple sub-agents.
Performance Context and Competitive Positioning
The 30-hour coding claim requires some unpacking. This doesn’t mean the model literally works for 30 consecutive hours on a single task—rather, it can maintain context and consistency across extended development sessions that would span that timeframe if performed by a human developer. The practical implication: developers can assign complex, multi-component projects and trust the model to maintain architectural coherence across the entire build.
The SWE-Bench Verified score of 77.2% represents substantial progress but also highlights remaining limitations. Nearly a quarter of real-world programming challenges still exceed the model’s capabilities. The benchmark tests whether AI can resolve actual GitHub issues from popular open-source repositories, making it more demanding than synthetic coding assessments. For context, human expert developers typically score in the 90%+ range on similar evaluations.
The OSWorld benchmark improvement from 42.2% to 61.4% in four months demonstrates rapid capability growth in computer control tasks. This metric measures how well AI systems can navigate operating systems, use applications, and complete multi-step workflows—skills essential for truly autonomous software development beyond pure code generation.
Anthropic’s alignment improvements address concerns that emerged with previous high-capability models. “Sycophancy” refers to AI systems telling users what they want to hear rather than providing accurate information. “Power-seeking” behaviors involve the model attempting to preserve itself or expand its influence in unintended ways. These safety enhancements matter more as models gain autonomy and handle sensitive tasks with less human oversight.
The checkpoint feature addresses a practical frustration developers experienced with earlier versions. Long coding sessions could derail if the model made an error deep into a project, forcing developers to start over or spend significant time correcting cascading mistakes. Checkpoint functionality lets developers establish “save points” and branch from earlier states if the model’s direction proves unproductive.
The Agent SDK release signals Anthropic’s platform strategy beyond direct Claude usage. By providing the infrastructure powering their own tools, they enable third-party developers to build specialized autonomous agents for specific industries or workflows. This approach mirrors how cloud platforms succeed—not just by offering services, but by enabling others to build on top of their technology.
Pricing details weren’t disclosed in the announcement, though previous Claude models have positioned themselves competitively against OpenAI’s GPT-4 offerings. The 30-hour autonomous capability could justify premium pricing for enterprise customers who can eliminate significant engineering time, but accessibility for individual developers and smaller teams will influence adoption rates.
The timing arrives amid intensifying competition in AI coding assistants, with GitHub Copilot, Amazon CodeWhisperer, and various startups all competing for developer mindshare. Anthropic’s emphasis on extended autonomous work differentiates Claude Sonnet 4.5 from tools focused on inline suggestions or discrete function generation—this positions the model for larger-scale architectural tasks rather than incremental productivity gains.



Post a comment